Learning-based robotic manipulation in cluttered environments
This research was conducted in Automation and Robotics Lab of Aristotle University of Thessaloniki.
Publications

Learning Push-Grasping in Dense Clutter
IEEE RAL 2022
Robotic grasping in highly cluttered environments remains a challenging task due to the lack of collision free grasp affordances. In such conditions, non-prehensile actions could help to increase such affordances. We propose a multi-fingered push-grasping policy that creates enough space for the fingers to wrap around an object to perform a stable power grasp, using a single primitive action. Our approach learns a direct mapping from visual observations to actions and is trained in a fully end-to-end manner. To achieve a more efficient learning, we decouple the action space by learning separately the robot hand pose and finger configuration. Experiments in simulation demonstrate that the proposed push-grasping policy achieves higher grasp success rate over baselines and that can generalize to unseen objects. Furthermore, although training is performed in simulation the learned policy is robustly transferred to a real environment without a significant drop in success rate.
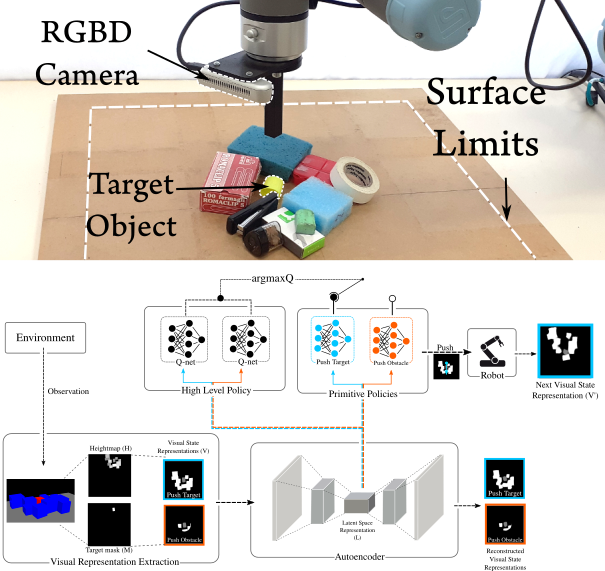
Total Singulation with Modular Reinforcement Learning
RAL 2021
Prehensile robotic grasping of a target object in clutter is challenging because, in such conditions, the target touches other objects, resulting to the lack of collision free grasp affordances. To address this problem, we propose a modular reinforcement learning method which uses continuous actions to totally singulate the target object from its surrounding clutter. A high level policy selects between pushing primitives, which are learned separately. Prior knowledge is effectively incorporated into learning, through action primitives and feature selection increasing sample efficiency. Experiments demonstrate that the proposed method considerably outperforms the state-of-the-art methods in the singulation task. Furthermore, although training is performed in simulation the learned policy is robustly transferred to a real environment without a significant drop in success rate. Finally, singulation tasks in different environments are addressed by easily adding a new primitive and by retraining only the high level policy.

Split Deep Q-Learning for Robust Object Singulation
ICRA 2020
Extracting a known target object from a pile of other objects in a cluttered environment is a challenging robotic manipulation task encountered in many robotic applications. In such conditions, the target object touches or is covered by adjacent obstacle objects, thus rendering traditional grasping techniques ineffective. In this paper, we propose a pushing policy aiming at singulating the target object from its surrounding clutter, by means of lateral pushing movements of both the neighboring objects and the target object until sufficient 'grasping room' has been achieved. To achieve the above goal we employ reinforcement learning and particularly Deep Q-learning (DQN) to learn optimal push policies by trial and error. A novel Split DQN is proposed to improve the learning rate and increase the modularity of the algorithm. Experiments show that although learning is performed in a simulated environment the transfer of learned policies to a real environment is effective thanks to robust feature selection. Finally, we demonstrate that the modularity of the algorithm allows the addition of extra primitives without retraining the model from scratch.

Robust object grasping in clutter via singulation
ICRA 2019
Grasping objects in a cluttered environment is challenging due to the lack of collision free grasp affordances. In such conditions, the target object touches or is covered by other objects in the scene, resulting in a failed grasp. To address this problem, we propose a strategy of singulating the object from its surrounding clutter, which consists of previously unseen objects, by means of lateral pushing movements. We employ reinforcement learning for obtaining optimal push policies given depth observations of the scene. The action-value function(Q-function) is approximated with a deep neural network. We train the robot in simulation and we demonstrate that the transfer of learned policies to the real environment is robust.